OME-Remote Objects¶
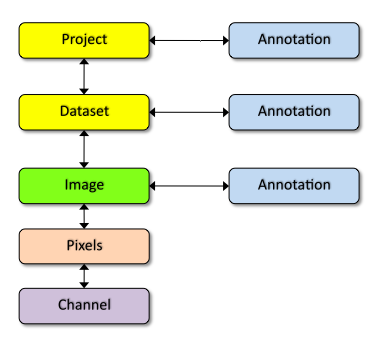
OMERO is based on the OME data model which can appear overly complex for new users. However, the core entities you need for getting started are much simpler.
Images in OMERO are organized into a many-to-many container hierarchy: “Project” -> “Dataset” -> “Image”. These containers (and various other objects) can be annotated to link various types of data. Annotation types include Comment (string), Tag (short string), Boolean, Long, Xml, File attachment etc.
Images are represented as Pixels with 5 dimensions: X, Y, Z, Channel, Time.
At the core of the work on the Open Microscopy Environment is the definition of a vocabulary for working with microscopic data. This vocabulary has a representation in the XML specification, in the database (the data model), and in code. This last representation is the object model with which we will concern ourselves here.
Because of its complexity, the object model is generated from a central definition using our own code-generator. It relies on no libraries and can be used in both the server and the RMI clients. The relationships among the objects are enumerated in a cross-referenced reference document. OMERO.blitz uses a second mapping to generate OMERO Java language bindings, OMERO Python language bindings, and OMERO C++ language bindings classes, which can be mapped back and forth to the server object model. This document discusses only the server object-model and how it is used internally.
Instances of the object model have no direct interaction with the database, rather the mapping is handled externally by the O/R framework, Hibernate. That means, by and large, generated classes are data objects, composed only of getter and setter fields for fields representing columns in the database, and contain no business logic. However, to make working with the model easier, and perhaps more powerful, there are several features which we have built in.
Note
The discussion here of object types is still relevant but uses the ome.model.* objects for examples. These are server internal types which may lead to some confusion. Clients work with omero.model.* objects. This documentation will eventually be updated to reflect both hierarchies.
OMERO type language¶
The Model has two general parts: first, the long-studied and well-established core model and second, the user-specified portion. It is vital that there is a central definition of both parts of the object model. To allow users to easily define new types, we need a simple domain specific language (or little language) which can be mapped to Hibernate mapping files. See an example at:
From this DSL, various artifacts can be generated: XML Schema, Java classes, SQL for generating tables, etc. The ultimate goal is to have no exceptions in the model.
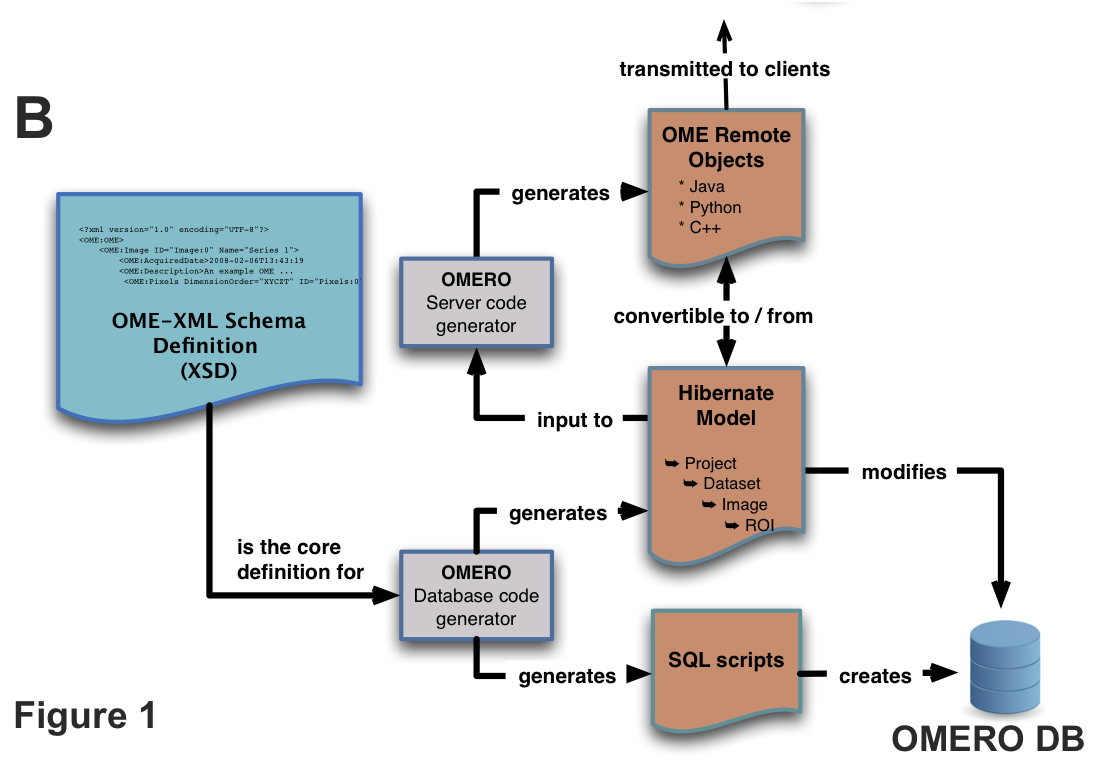
Conceptually, the XSD files under the components/specification
source directory are the starting point for all code generation. Currently
however, the files under components/model/resources/mappings
are hand-written based on the XSD files.
The ant task created from the components/dsl/src Java files
is then used to turn the mapping files into generated Java code under the
model/target/generated/src directory. These classes are all within the
ome.model package. A few hand-written Java classes can also be found in
components/model/src/ome/model/internal.
The build-schema ant target takes the generated ome.model classes as
input and generates the sql/psql scripts which get used by
omero db script to generate a working OMERO database. Files named
like OMEROVERSION__PATCH.sql are hand-written update scripts.
The primary consumer of the ome.model classes at runtime is the components/server component.
The above classes are considered the internal server code, and are the only objects which can take part in Hibernate transactions.
External to the server code is the “blitz” layer. These classes are in the
omero.model package. They are generated by another call to the DSL ant task
in order to generate the Java, Python, C++, and Ice files under
components/blitz/generated.
The generated Ice files along with the hand-written Ice files from
components/blitz/resources/omero are then run through the
slice2cpp, slice2java, and slice2py command-line utilities in
order to generate source code in each of these languages. Clients pass in
instances of these omero.model (or in the case of C++, omero::model) objects.
These are transformed to ome.model objects, and then persisted to the
database.
If we take a concrete example, a C++ client might create an Image via new
omero::model::ImageI(). The “I” suffix represents an “implementation” in
the Ice naming scheme and this subclasses from omero::model::Image. This can
be remotely passed to the server which will be deserialized as an
omero.model.ImageI object. This will then get converted to an
ome.model.core.Image, which can finally be persisted to the database.
Keywords¶
Some words are not allowed as properties/fields of OMERO types. These include:
- id
- version
- details
- … any SQL keyword
Improving generated data objects¶
Constructors¶
Two special constructors are generated for each model object. One is for creating proxy instances, and the other is for filling all NOT-NULL fields:
Pixels p_proxy = new Pixels(Long, boolean);
Pixels p_filled = new Pixels(ome.model.core.Image, ome.model.enums.PixelsType,
java.lang.Integer, java.lang.Integer, java.lang.Integer, java.lang.Integer, java.lang.Integer,
java.lang.String, ome.model.enums.DimensionOrder, ome.model.core.PixelsDimensions);
The first should almost always be used as: new Pixels(5L, false).
Passing in an argument of true would imply that this object is
actually loaded, and therefore the server would attempt to null all the
fields on your object. See below for a discussion on loadedness.
In the special case of Enumerations, a constructor is generated
which takes the value field for the enumeration:
Format file_format = new Format("text/plain");
Further, this is the only example of a managed object which will be
loaded by the server without its id. This allows applications to
record only the string "text/plain" and not need to know the actual id
value for "text/plain".
Details¶
Each table in the database has several columns handling low-level matters such as security, ownership, and provenance. To hide some of these details in the object model, each IObject instance contains an ome.model.internal.Details instance.
Details works something like unix’s stat:
/Types/Images>ls -ltrAG
total 0
-rw------- 1 josh 0 2006-01-25 20:40 Image1
-rw------- 1 josh 0 2006-01-25 20:40 Image2
-rw------- 1 josh 0 2006-01-25 20:40 Image3
-rw-r--r-- 1 josh 0 2006-01-25 20:40 Image100
/Types/Images>stat Image1
File: `Image1'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 1602h/5634d Inode: 376221 Links: 1
Access: (0600/-rw-------) Uid: ( 1003/ josh) Gid: ( 1001/ ome)
Access: 2006-01-25 20:40:30.000000000 +0100
Modify: 2006-01-25 20:40:30.000000000 +0100
Change: 2006-01-25 20:40:30.000000000 +0100
though it can also store arbitrary other attributes (meta-metadata, so to speak) about our model instances. See Dynamic methods below for more information.
The main methods on Details are:
Permissions Details.getPermissions();
List Details.getUpdates();
Event Details.getCreationEvent();
Event Details.getUpdateEvent();
Experimenter Details.getOwner();
ExperimenterGroup Details.getGroup();
ExternalInfo getExternalInfo();
though some of the methods will return null, if that column is not
available for the given object. See Interfaces below for more
information.
Consumers of the API are encouraged to pass around Details instances rather than specifying particulars, like:
if (securitySystem.allowLoad(Project.class, project.getDetails())) {}
// and not
if (project.getDetails().getPermissions().isGranted(USER,READ) && project.getDetails().getOwner().getId( myId )) {…}
This should hopefully save a good deal of re-coding if we move to true ACL rather than the current filesystem-like access control.
Because it is a field on every type, Details is also on the list of keywords in the type language (above).
Interfaces¶
To help work with the generated objects, several interfaces are added to their “implements” clause:
| Property | Applies_to | Interface | Notes |
| Base | |||
| owner | ! global | need sudo | |
| group | ! global | need sudo | |
| version | ! immutable | ||
| creationEvent | ! global | ||
| updateEvent | ! global && ! immutable | ||
| permissions | |||
| externalInfo | |||
| Other | |||
| name | Named | ||
| description | Described | ||
| linkedAnnotationList | IAnnotated | ||
For example, ome.model.meta.Experimenter is a “global” type,
therefore it has no Details.owner field. In order to create this
type of object, you will either need to have admin privileges, or in
some cases, use the ome.api.IAdmin interface directly (in the case
of enums, you will need to use the ome.api.ITypes interface).
Inheritance¶
Inheritance is supported in the object model. The superclass relationships can be defined simply in the mapping files. One example is the annotation hierarchy in components/model/resources/mappings/annotations.ome.xml. Hibernate supports this polymorphism, and will search all subclasses when a superclass is returned. However, due to Hibernate’s use of bytecode-generated proxies, testing for class equality is not always straightforward.
Hibernate uses CGLIB and Javassist and similar bytecode generation to perform much of its magic. For these bytecode generated objects, the getClass() method returns something of the form “ome.model.core.Image_$$_javassist” which cannot be passed back into Hibernate. Instead, we must first parse that class String with Utils#trueClass().
Model report objects¶
To support the Collection Counts
requirement in which users would like to know how many objects are in a
collection by owner, it was necessary to add read-only
Map<String, Long> fields to all objects with links. See the
Collection counts page for more information.
Dynamic methods¶
Finally, because not all programming fits into the static programming frame, the object model provides several methods for working dynamically with all IObject subclasses.
fieldSet / putAt / retrieve¶
Each model class contains a public final static String for each field in
that class (superclass fields are omitted). A copy of all these fields
is available through fieldSet(). This field identifier can be used in
combination with the putAt and retrieve methods to store arbitrary data
in a class instance. Calls to putAt/retrieve with a string found in
fieldSet delegate to the traditional getters/setters. Otherwise, the
value is stored in lazily-initialized Map (if no data is stored, the
map is null).
acceptFilter¶
An automation of calls to putAt / retrieve can be achieved by
implementing an ome.util.Filter. A Filter is a VisitorPattern-like
interface which not only visits every field of an object, but also has
the chance to replace the field value with an arbitrary other value.
Much of the internal functionality in OMERO is achieved through filters.
Limitations¶
- The filter methods override all standard checks such as IObject#isLoaded and so null-pointer exceptions etc. may be thrown.
- The types stored in the dynamic map currently do not propagate to the OMERO.blitz model objects, since not all java.lang.Objects can be converted.
Entity lifecycle¶
These additions make certain operations on the model objects easier and cleaner, but they do not save the developer from understanding how each object interacts with Hibernate. Each object has a defined lifecycle and it is important to know both the origin (client, server, or backend) as well as its current state to understand what will and can happen with it.
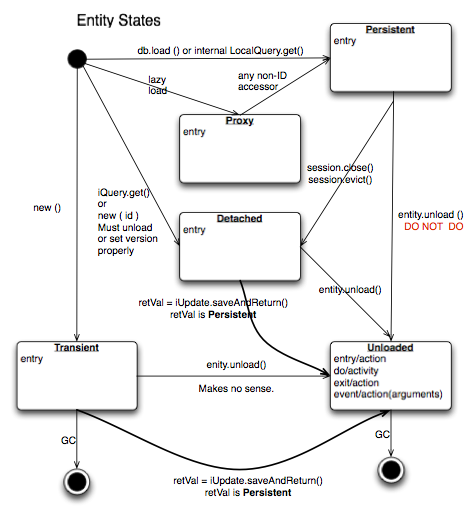
States¶
Each instance can be found in one of several states. Quickly, they are:
- transient
- The entity has been created (
"new Image()") and not yet shown to the backend. - persistent
- The entity has been stored in the database and has a non-
nullid (IObject.getId()). Here Hibernate differentiates between detached, managed, and deleted entities. Detached entities do not take part in lazy-loading or dirty detection like managed entities do. They can, however, be re-attached (made “managed”). Deleted entities cannot take part in most of the ORM activities, and exceptions will be thrown if they are encountered. - unloaded (a reference, or proxy)
- To solve the common problem of lazy loading exceptions found in many
Hibernate applications, we have introduced the concept of unloaded
proxy objects which are objects with all fields nulled other than
the id. Attempts to get or set any other property will result in an
exception. The backend detects these proxies and restores their
value before operating on the graph. There are two related states
for collections –
nullwhich is completely unloaded, and filtered in which certain items have been removed (more on this below).
Identity, references, and versions¶
Critical for understanding these states is understanding the concepts of
identity and versioning as it relates to ORM. Every object has an id
field that if created by the backend will not be null. However,
every table does not have a primary key field – subclasses contain a foreign
key link to their superclass. Therefore all objects without an id are
assumed to be non-persistent (i.e. transient).
Though the id cannot be the sole decider of equality since there are issues with the Java definition of equals() and hashCode(), we often perform lookups based on the class and id of an instance. Here again caution must be taken not to unintentionally use a possibly bytecode-generated subclass. See the discussion under Inheritance above.
Class/id-based lookup is in fact so useful that it is possible to take
an model object and call obj.unload() to have a “reference” –
essentially a placeholder for a model object that contains only an id.
Calls to any accessors other than get/setId will throw an exception. An
object can be tested for loadedness with obj.isLoaded().
A client can use unloaded instances to inform the backend that a certain information is not available and should be filled in server-side. For example, a user can do the following:
Project p = new Project();
Dataset d = new Dataset( new Long(1), false); // this means create an already unloaded instance
p.linkDataset(d);
iUpdate.saveObject(p);
The server, in turn, also uses references to replace backend proxies
that would otherwise throw LazyInitializationExceptions on
serialization. Clients, therefore, must code with the expectation that
the leaves in an object graph may be unloaded. Extending a query with
“outer join fetch” will cause these objects to be loaded as well. For
example:
select p from Project p
left outer join fetch p.datasetLinks as links
left outer join fetch links.child as dataset
but eventually in the complex OME metadata graph, it is certain that something will remain unloaded.
Versions are the last piece to understanding object identity. Two entities with the same id should not be considered equal if they have differing versions. On each write operation, the version of an entity is incremented. This allows us to perform optimistic locking so that two users do not simultaneously edit the same object. That works so:
- User A and User B retrieve Object X id=1, version=0.
- User A edits Object X and saves it. Version is incremented to 1.
- User B edits Object X and tries to save it. The SQL generated is: UPDATE table SET value = newvalue WHERE id = 1 and version = 0; which upates no rows.
- The fact that no rows were altered is seen by the backend and an
OptimisticLockExceptionis thrown.
Identity and versioning make working with the object model difficult sometimes, but guarantee that our data is never corrupted.
Working with the object model¶
With these states in mind, it is possible to start looking at how to actually use model objects. From the point of view of the server, everything is either an assertion of an object graph (a “write”) or a request for an object graph (a “read”), whether they are coming from an RMI client, an OMERO.blitz client, or even being generated internally.
Writing¶
Creating new objects is as simple as instantiating objects and linking
them together. If all NOT-NULL fields are not filled, then a
ValidationException will be thrown by the server:
IUpdate update = new ServiceFactory().getUpdateService();
Image i = new Image();
try {
update.saveObject(i);
catch (ValidationException ve) {
// not ok.
}
i.setName("image");
return update.saveAndReturnObject(i); // ok.
Otherwise, the returned value will be the Image with its id field filled. This works on arbitrarily complex graphs of objects:
Image i = new Image("image-name"); // This constructor exists because "name" is the only required field.
Dataset d = new Dataset("dataset-name");
TagAnnotation tag = new TagAnnotation();
tag.setTextValue("some-tag");
i.linkDataset(d);
i.linkAnnotation(tag);
update.saveAndReturnObject(i);
Reading¶
Reading is a similarly straightforward operation. From a simple id-based
lookup, iQuery.get(Experimenter.class, 1L) to a search for an
arbitrarily complex graph:
Image i = iQuery.findByQuery("select i from Image i "+
"join fetch i.datasetLinks as dlinks "+
"join fetch i.annotationLinks as alinks "+
"join fetch i.details.owner as owner "+
"join fetch owner.details.creationEvent "+
"where i.id = :id", new Parameters().addId(1L));
In the return graph, you are guaranteed that any two instances of the same class with the same id are the same object. For example:
Image i = …; // From query
Dataset d = i.linkedDatasetList().get(0);
Image i2 = d.linkedImageList().get(0);
if (i.getId().equals(i2.getId()) {
assert i == i2 : "Instances must be referentially equal";
}
Reading and writing¶
Complications arise when you try to mix objects from different read
operations because of the difference in equality. In all but the most
straightforward applications, references to IObject instances from
different return graphs will start to intermingle. For example, when a
user logins in, you might query for all Projects belonging to the user:
List<Project> projects = iQuery.findAllByQuery("select p from Project p where p.details.owner.omeName = someUser", null);
Project p = projects.get(0);
Long id = p.getId();
Later you might query for Datasets, and be returned some of the same Projects again within the same graph. You have now possibly got two versions of the Project with a given id within your application. And if one of those Projects has a new Dataset reference, then Hibernate would not know whether the object should be removed or not.
Project oldProject = …; // Acquired from first query
// Do some other work
Dataset dataset = iQuery.findByQuery("select d from Dataset d "+
"join fetch d.projectsLinks links "+
"join fetch links.parent "+
"where d.id = :id", new Parameters().addId(5L));
Project newProject = dataset.linkedProjectList().get(0);
assert newProject.getId().equals(oldProject.getId()) : "same object";
assert newProject.sizeOfDatasetLinks() == oldProject.sizeOfDatasetLinks() :
"if this is false, then saving oldProject is a problem";
Without optimistic locks, trying to save oldProject
would cause whatever Datasets were missing from it to be removed from
newProject as well. Instead, an OptimisticLockException is thrown
if a user tries to change an older reference to an entity. Similar
problems also arise in multi-user settings, when two users try to access
the same object, but it is not purely due to multiple users or even
multiple threads, but simply due to stale state.
Note
There is an issue with multiple users in which a
SecurityViolation is thrown instead of an OptimisticLockException.
Various techniques to help to manage these duplications are:
- Copy all data to your own model.
- Return unloaded objects wherever possible.
- Be very careful about the operations you commit and about the order they take place in.
- Use a
ClientSession.
Lazy loading¶
An issue related to identity is lazy loading. When an object graph is requested, Hibernate loads only the objects which are directly requested. All others are replaced with proxy objects. Within the Hibernate session, these objects are “active” and if accessed, they will be automatically loaded. This is taken care of by the first-level cache, and is also the reason that referential equality is guaranteed within the Hibernate session. Outside of the session however, the proxies can no longer be loaded and so they cannot be serialized to the client.
Instead, as the return value passes through OMERO’s AOP layer, they get disconnected. Single-valued fields are replaced by an unloaded version:
OriginalFile ofile = …; // Object to test
if ( ! Hibernate.isInitialized( ofile.getFormat() ) {
ofile.setFormat( new Format( ofile.getFormat().getId(), false) );
}
Multi-valued fields, or collections, are simply nulled. In this case,
the sizeOfXXX method will return a value less than zero:
Dataset d = …; // Dataset obtained from a query. Didn't request Projects
assert d.sizeOfProjects() < 0 : "Projects should not be loaded";
This is why it is necessary to specify all “join fetch” clauses for instances which are required on the client-side. See ProxyCleanupFilter for the implementation.
Collections¶
More than just the nulling during serialization, collections pose several interesting problems.
For example, a collection may be filtered on retrieval:
Dataset d = iQuery.findByQuery("select d from Dataset d "+
"join fetch d.projectLinks links "+
"where links.parent.id > 2000", null);
Some ProjectDatasetLink instances have been filtered from the
projectLinks collection. If the client decides to save this collection
back, there is no way to know that it is incomplete, and Hibernate will
remove the missing Projects from the Dataset. It is the developer’s
responsibility to know what state a collection is in. In the case of
links, discussed below, one solution is to use the link objects
directly, even if they are largely hidden with the API, but the problem
remains for 1-N collections.
Links¶
A special form of links collection model the many-to-many
relationship between two other objects. A Project can contain any number
of Datasets, and a Dataset can be in any number of Projects. This is
achieved by ProjectDatasetLinks, which have a Project “parent” and a
Dataset “child” (the parent/child terms are somewhat arbitrary but are
intended to fit roughly with the users’ expectations for those types).
It is possible to both add and remove a link directly:
ProjectDatasetLink link = new ProjectDatasetLink();
link.setParent( someProject );
link.setChild( someDataset );
link = update.saveAndReturnObject( link );
// someDataset is now included in someProject
update.deleteObject(link);
// or update.deleteObject(new ProjectDatasetLink(link.getId(), false)); // a proxy
// Now the Dataset is not included,
// __unless__ there was already another link.
However, it is also possible to have the links managed for you:
someProject.linkDataset( someDataset ); // This creates the link
update.saveObject( someProject ); // Notices added link, and saves it
someProject.unlinkDataset( someDataset );
update.saveObject( someProject ); // Notices removal, and deletes it
The difficulty with this approach is that unlinkDataset() will fail
if the someDataset which you are trying to remove is not referentially
equal. That is:
someProject.linkDataset( someDataset );
updatedProject = update.saveAndReturnObject( someProject );
updatedProject.unlinkDataset( someDataset );
update.saveObject( updateProject ); // will do __nothing__ !
does not work since someDataset is not included in updatedProject, but rather updatedDataset with the same id is. Therefore, it would be necessary to do something along the following lines of:
updatedProject = …; // As before
for (Dataset updatedDataset : updatedProject.linkedDatasetList() ) {
if (updatedDataset.getId().equals( someDataset.getId() )) {
updatedProject.unlinkDataset( updatedDataset );
}
}
The unlink method in this case, removes the link from both the Project.datasetLinks collection as well as from the Dataset.projectLinks collection. Hibernate notices that both collections are in agreement, and deletes the ProjectDatasetLink (this is achieved via the “delete-orphan” annotation in Hibernate). If only one side of the collection has had its link removed, an exception will be thrown.
Synchronization¶
Another important point is that the model objects are in no way synchronized. All synchronization must occur within application code.
Limitations¶
We try to minimize differences between the Model as described by the XML specification and its implementation in the OMERO database but some Objects may behave in a more restricted fashion within OMERO. Examples include:
- ROIs and rendering settings can only belong to one Image
