Note
This documentation is for OMERO 5.2. This version is now in maintenance mode and will only be updated in the event of critical bugs or security concerns. OMERO 5.3 is expected before the end of 2016.
Import under OMERO.fs¶
The OMERO 5 release introduces OMERO.fs, a new way of storing files in the OMERO binary repository and thus a new method of importing images to the server.
In previous versions of OMERO the import process was very much client-centered. When importing an image the client pushed pixel data, metadata and, optionally, original image files to the OMERO server. With the advent of OMERO 5, OMERO.fs allows the pixels to be accessed directly from the original image files. This means that much of the import process can now take place on the server once the original image files have been uploaded.
This page looks at the implications for the developer writing import clients. A broad description of the import workflow is followed by some of the model changes needed to facilitate this workflow. The current API sequence is then introduced before looking at server-side classes and sequence. Finally, the configuration required for OMERO.fs is specified.
Import overview¶
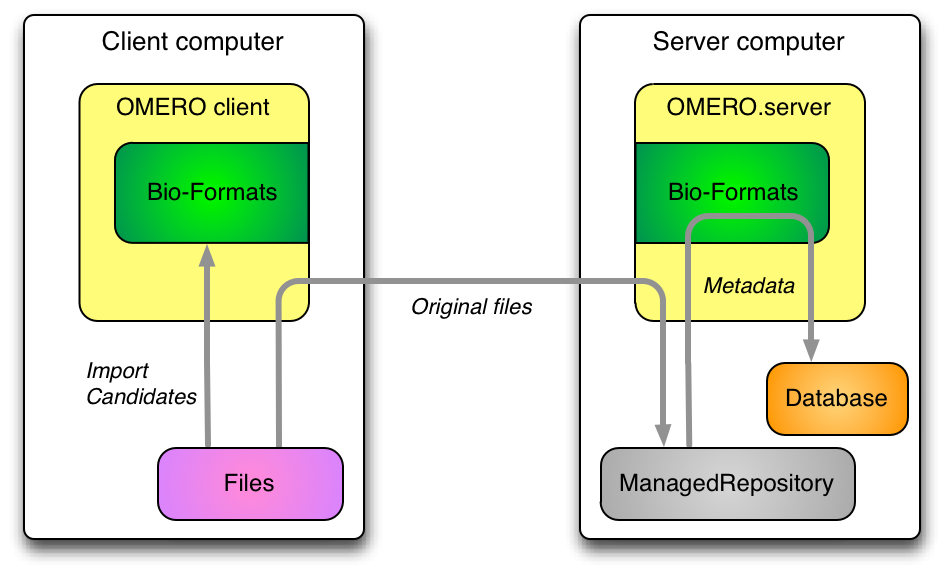
The broad import workflow comprises selecting a file or set of files to be imported client-side. Using Bio-Formats on the client this selection is resolved into a number of import candidates. Here an import candidate is a file or set of files that represents a single image, a multi-image set or a plate. Each import candidate, which may be one file or several files, is then treated as Fileset for import. The import of each Fileset is then undertaken by the client in two stages: upload and server-side import.
A Fileset is uploaded to the server into a location determined by the server, multiple Filesets may be uploaded in parallel by a client. A checksum is calculated before upload by the client and after upload by the server. If these checksums match then the client triggers a server-side import. The client can then move on to doing other work and leave the import to complete on the server.
Once the Fileset is on the server and an import has been initiated by the client all processing then takes place on the server. The server then uses Bio-Formats to extract and store the metadata, calculate the minimum and maximum pixel values and do other import processing.
Filesets¶
A fileset is a concept new to OMERO.fs which captures how Bio-Formats relates files to the images that they encode. If importing a single file leads to a single corresponding image being viewable then a one-to-one mapping exists from file to image. However, an image’s information may be split among multiple files, or a single file may encode multiple images. In other cases, especially in high-content screening, many images of wells may be encoded in a complex manner by many files. In all these cases, a fileset is used to hold the set of files and the set of images to which those files correspond.
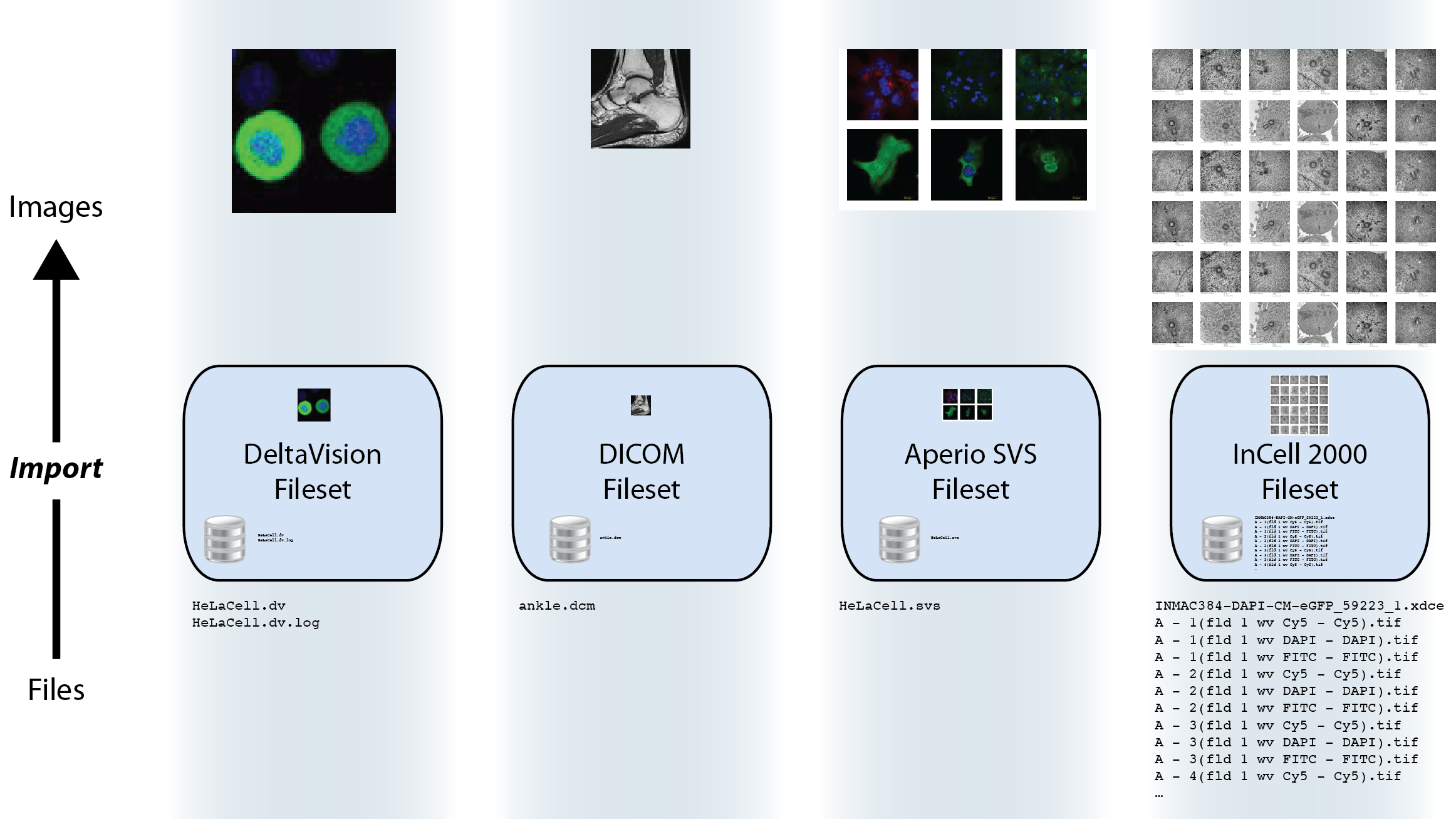
Filesets are essentially indivisible: the files or images that a fileset represents are deleted, or moved between groups, only as one unit together, and on the server each fileset has a directory in which only its files are stored. Each fileset firmly binds sets of files and images because the dependencies among them mean that splitting components away leaves a partial fileset making the remaining data unreadable. Similarly, you should not rename any components of a fileset as this will also break the dependencies holding them together.
Model description¶
See acquisition.ome.xml.
- ome.model.fs.Fileset
- Represents a group of files which are considered to belong together.
- In the future the client may upload a single “import set” that is subsequently resolved by Bio-Formats into multiple filesets on the server.
- Also links to multiple ome.model.jobs.Job instances.
- Links to the image objects that are created during import.
- ome.model.jobs.Job subclasses
- Each one represents some action which takes place server-side on the Fileset.
- For the standard sequence described above, the first will always be an UploadJob which contains version info from the client. If the files were not uploaded however, this may not be the case. Then a MetadataImportJob follows, which is the basic import.
- Other jobs may be necessary for regular usage (PixelDataJob, IndexingJob, etc.). Later jobs may also be added like a re-parse job, a re-check of the hashes to detect corruption, or an archive job.
- For job definitions, see jobs.ome.xml.
- Some subclasses have a versionInfo property for storing a snapshot of process information along with software versions. Most important for knowing how files were parsed, therefore when using importPaths, a “synthetic” version info might be created to say that these were just uploaded blindly.
- ome.model.fs.FilesetEntry
- Link from a Fileset to exactly one ome.model.core.OriginalFile
- Critically, it also contains the original absolute client path of that file.
API sequence¶
- Choose which files to import by either:
- ImportLibrary and friends (Java only)
- listing all files (not directories) manually.
- Choose a ManagedRepositoryPrx from SharedResourcesPrx.repositories().
- Call either:
- ImportLibrary.importImage() which calls ManagedRepositoryPrx.importFilesets(Fileset, ImportSettings), or
- directly use ManagedRepositoryPrx.importPaths(StringSet).
- Receive an ImportProcessPrx.
- For each FileEntry in the FileSet or each path in the StringSet (in order), call ImportProcessPrx.getUploader() and receive a RawFileStorePrx.
- Upload the file via RawFileStorePrx.write() while reading the files locally to write, be sure to calculate the checksum.
- Pass a list of checksums (in order) to ImportProcessPrx.verifyUpload(StringSet). If the hashes match, receive a HandlePrx. Otherwise an exception is thrown.
At this point, the client should be able to disconnect and the rest of the import should happen independently.
- Create an CmdCallbackI that wraps the HandlePrx and wait for successful completion.
At this point, the main metadata import is finished, but background processing may still be occurring. Handles for the background processing will also be returned.
Server-side classes/concepts¶
AbstractRepositoryI and all of its subclasses are implementations of the InternalRepository API. These objects are for internal use only and should never be accessible by the clients. Each instance is initialized with a directory which the servant attempts to “acquire” (i.e. grab a lock file). Once it does so, it is the serving repository.
Each internal repository provides a public view which in turn provides the Repository API. All method calls assume Unix-style strings, which are guaranteed by CheckedPath, a loose wrapper around java.io.File. CheckedPath objects along with the active Ice.Current instance are passed to the RepositoryDao interface, which provides database access for all repositories. Access to raw IO is provided by the RepoRawFileStoreI servant, which wraps a RawFileBean.
The ManagedRepository implementation is responsible for import and enforces further constraints (beyond those of CheckedPath) on where and what files are created. Most importantly, the omero.fs.repo.path template value is expanded and pre-pended to all uploads. A further responsibility of the ManagedRepository is to maintain a list of all currently running ManagedImportProcessI, each of which is held in the ProcessContainer. These ManagedImportProcessI instances further wrap RepoRawFileStoreI instances with a subclass, ManagedRawFileStoreI.
For file import through ManagedRepository.importFileset, although hasher is nullable ordinarily, it will be set through the mandatory ImportSettings.checksumAlgorithm property. ManagedRepository.listChecksumAlgorithms lists the hashers supported by the server. ManagedRepository.suggestChecksumAlgorithm helps the client and server to negotiate a mutually acceptable algorithm, as in ImportLibrary.createImport; the result is affected by the server’s configuration setting for omero.checksum.supported. ImportLibrary calculates each file’s hash using hashers obtained through ChecksumProviderFactory.getProvider. In fetching OriginalFile objects by HQL through the Query Service one needs JOIN FETCH on the hasher property to read the hasher’s name.
Server-side sequence¶
NB: Server-side ImportLibrary is no longer being used. That logic is currently moved to ManagedImportRequestI. This may not be the best location. Further, several other layers might also be collapsible, like OMEROMetadataStore which is currently accessible as a “hidden” service MetadataStorePrx. Here, “hidden” means that it is not directly retrievable from ServiceFactoryPrx.
- ManagedRepositoryI.importPaths()
- reuses ImportContainer.fillData() to create an ImportSettings and a Fileset and then calls importFileset(Fileset, ImportSettings)
- ManagedRepositoryI.importFileset()
- determines an ImportLocation calling PublicRepositoryI.makeDir() where necessary.
- createImportProcess creates a ManagedImportProcessI, registers it, and returns it.
- After this, the repository is only responsible for periodically having the ping and eventually the shutdown method called, via ProcessContainer.
- ManagedImportProcessI.getUploader()
- creates a new RepositoryRawFileStoreI for each file in the paths/fileset.
- Once close() is called on this instance, closeCalled(int i) will be called on the import process and the instance will be removed.
- If getUploader() is called again, then a new file store will be created.
- ManagedImportProcessI.verifyUpload()
- If all hashes match, then a ManagedImportRequestI instance is created and submitted to omero.cmd.SessionI.submit_async() for background processing. The client can wait for the returned omero.cmd.HandlePrx to finish by using a CmdCallbackI.
- At this point, the ImportProcessPrx can be closed as well as the entire client and the import would still continue. Only if HandlePrx.cancel() is called, will the import be aborted.
- QUESTION: How to handle rollback at this point?
- ManagedImportRequestI.init (within transaction)
- Registry.getInternalServiceFactory() grabs a ServiceFactoryPrx without the need for an omero.client instance.
- OMEROWrapper and a OMEROMetadataStoreClient are created with this connection.
- Some other basic configuration takes place.
- ManagedImportRequest.step() (N times, each within same transaction as
init())
- NB: it may later make more sense for this bit to happen in a separate process.
- At the moment, 5 steps are hard-coded. Each performing roughly the same
amount of work. Some of these may later be done in the background.
- importMetadata() calls store.saveToDB(), which calls MetadataStorePrx.saveToDb(), a remote call. This could possibly be inlined.
- generateThumbnails() calls store.resetDefaultsAndGenerateThumbnails(), another remote call, which could also be inlined.
- pixelData() calls store.setPixelsParams(), updatePixels(), and populateMinMax(). Min/Max especially should be backgrounded.
- Finally, store.launchProcessing() is called, which should remain, but could also be inlined. The returned script processes could be returned in the ImportResponse.
- Return appropriate values.
- notifyObservers() currently does nothing, since this was client-side functionality in ImportLibrary. This needs to be replaced!
- ManagedImportRequest.buildResponse() (N times, outside the transaction)
- Only step 4 does anything, storing the pixels in a ImportResponse
- ManagedImportRequest.getResponse() (1 time, regardless of exception or
not)
- Performs cleanup, then returns the ImportResponse assuming that no call to helper.cancel() has been made. At this point, ImportLibrary.importImage() returns successfully.
See also